I've been thinking about setting up Anubis to protect my blog from AI scrapers, but I'm not clear on whether this would also block search engines. It would, wouldn't it?
danielquinn
joined 2 years ago
Was it "social media" or was it specific tech companies trading rage for clicks? I find it hard to believe that Mastodon & Lemmy would be comparable to X & Facebook in this area.
I use them quite heavily in combination with Cookie Autodelete. I then create a separate profile for each surveillance capitalist service I work with. So for example, here's my list of containers:

Every time I visit one of these sites, Firefox opens them in the respective container, and the cookies they create are isolated to that container. When I'm in the LinkedIn container, Cookie AutoDelete nukes every cookie that isn't from LinkedIn (including Google, GitHub, etc.). When I'm not in any container, all cookies are deleted everywhere.
Basically it's a nice way to leverage Cookie Autodelete without having to whitelist Big Tech for all my browsing.
I should hope that they're right. We should return what was stolen.
You do not need to pave green space to build homes. There's plenty of paved, ugly, low-density areas in desperate need of upgrades. The problem is the British public's obsession with that idea that everyone needs their own patch of grass and two cars.
As someone else said here, programmers are not a monolith. However, I've seen it multiple times on the job and in social media where programmers are using these tools to write code voluntarily. The code produced is often garbage, and I have to reject it at review time, but there are a lot of programmers using these things willingly.
I had a job interview a few weeks ago where the lead developer straight-up said that he doesn't have any tests in the codebase because "it's just writing your code twice". I thought he was joking. Unfortunately he was not.
I didn't end up getting the job, perhaps because I made it clear that I thought he was very wrong. I think I dodged a bullet.
Why would they do that? The current system ensures that at least one of them will always be in charge, and they effectively have the same politics.
They already do.
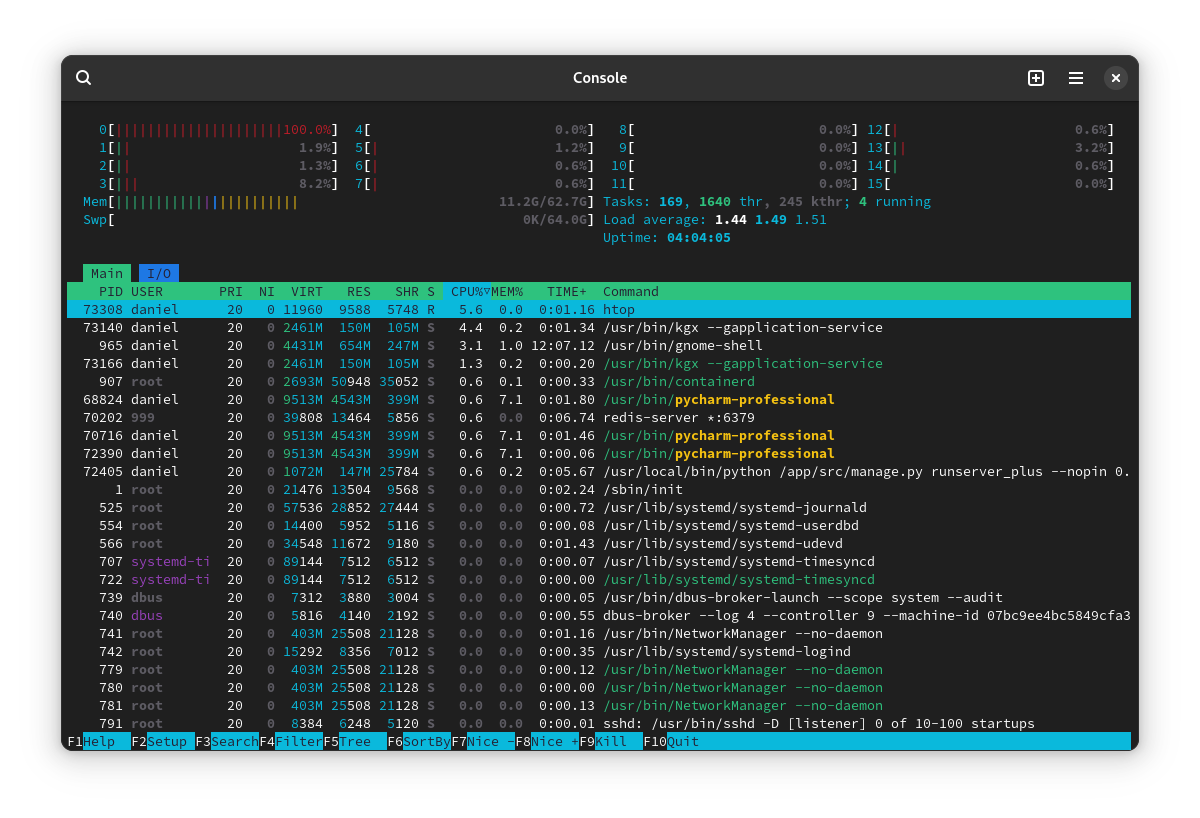
From time to time, often after I've restored from sleep or finished playing a Steam game, one of my CPU cores is pinned at 100% with no indication of what might be doing it. Running htop, btop, or GNOME system monitor all show the same thing: CPU0 at 100% while the rest are doing near-nothing, and no process in particular seems to be using those resources.
If I restart, it's back to normal, and sometimes I can play a game in Steam or let the computer go to sleep and it doesn't do this, but it happens often enough that's annoying/confusing so I'd like to know if there's a way to either (a) diagnose which processes are using which CPU cores, or (b) somehow "reset" the checking of these values to make sure that something's not just being misreported.
This is a desktop system running Arch & GNOME.
view more: next ›
This all appears to be based on the user agent, so wouldn't that mean that bad-faith scrapers could just declare themselves to be typical search engine user agent?